End-to-End AI-Driven Data Pipeline
Multi-stage pipeline orchestrating scraping, scoring, and personalised AI generation for B2B outbound. Multi-model routing, validator catches AI-pattern output, around 50% cold connection acceptance.
Built around methodology, not metrics. Validator logic, deterministic fallbacks, queue-based stage isolation, multi-model routing. Around 50% cold connection acceptance rate.
What this case study demonstrates
A Danish SMB accounting firm needed to scale LinkedIn outbound without hiring SDRs. The interesting work wasn’t the channel. It was the system underneath: research, scoring, multi-model AI generation with validation, and real-time signal routing into operational tools. This case study is about that system, not the channel.
Nine stages. Central queue keyed on entity ID. Each stage reads inputs from the queue and writes results back. Any stage can be rerun independently. Failures degrade gracefully to deterministic fallbacks rather than crashing the batch. AI is used where it earns its place. Deterministic logic does the rest.
Want the technical deep-dive: pipeline architecture, prompt design, validator logic, deployment? See the GitHub case study.
Outcome first
One metric that compounds: around 50% acceptance rate on cold LinkedIn connections. The threshold above which conversations actually start. Reaching it consistently is what proves the validator and personalisation layers are working as designed.
The system runs end-to-end on autopilot. The only human-in-the-loop step is a weekly review of outputs and a Monday-morning summary the system generates automatically. Everything else in this case study is the methodology that produces the number.
Context
The work was being done manually. The structural limit: per-record personalisation past a few hundred entities destroys the unit economics.
The constraint that shaped the build: every output had to be defensible. If reviewed manually, the data, the personalisation, and the structure all had to be something a domain expert would actually approve.
The problem
Two structural failure modes for systems like this:
- Manual personalisation doesn’t scale. Past a few hundred entities, the per-record time cost destroys the unit economics.
- Generic AI output gets ignored. The output reads like AI because it is AI. Acceptance collapses, trust collapses.
Most “AI-driven” pipelines solve the wrong half. They generate volume, not signal. They optimise for throughput rather than per-record quality. The interesting engineering problem is producing AI output that survives manual review at scale.
The approach
Four jobs the system has to do. AI gets used where it earns its place. Deterministic logic does the rest.
Define the fit profile as data, not intuition. The domain expert’s gut sense of “the right target” had to become hard filters (entity attributes from public registry data), soft signals (behavioural patterns, observable activity), and exclusion signals (existing relationships, suppression lists). The fit profile lives in a versioned config file. New segments are new entries. The pipeline picks them up on the next run.
Score every entity before acting. A composite score across fit (registry features), intent signals (observable activity), and engagement (existing context). The ML detection model plugs in here as a score boost. Acting on every entity is cheap. Acting on the wrong entities is expensive. The score decides the order.
Generate output that survives manual review. Three Claude calls per record, each with a different job. Read the data, draft the output, validate the output. The validator strips AI-pattern tells (em-dash overuse, three-item lists, “not just X but Y” constructions, factual claims not present in source data). If the validator score is below threshold, the output falls back to a deterministic template. Never to a raw AI miss.
Act on data in real time, not in batch. A positive reply triggers a CRM record within minutes. An auto-response gets parsed and the entity gets snoozed until the return date. A “not interested” reply gets logged and the entity moves to the suppression list. No manual triage.
The build
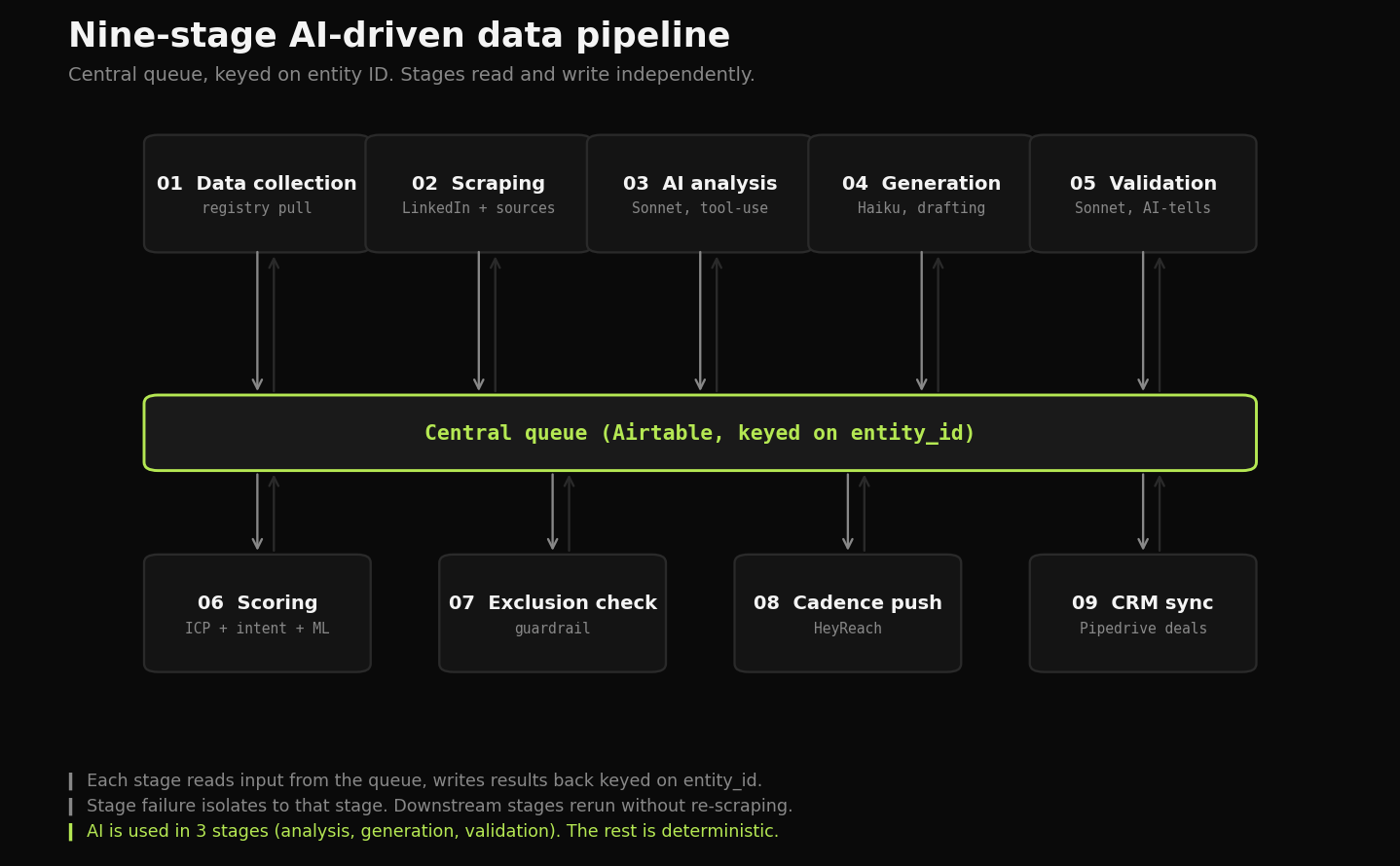 Nine-stage pipeline. Each stage reads from and writes to the central queue. Any stage can be rerun independently.
Nine-stage pipeline. Each stage reads from and writes to the central queue. Any stage can be rerun independently.
Each stage reads from and writes back to a central queue. Any stage can be rerun independently. This is the difference between a fragile demo and a system that ships.
Two things matter most in the build.
The AI layer is three Claude calls, not one. Cheap models for high-volume generation, expensive models for harder reasoning. Haiku writes the first draft. Sonnet does the fit assessment (the call where reasoning matters most) and the validation pass (where catching a bad output matters more than saving tokens). Cost stays predictable per record. Failures fall back to deterministic templates rather than crashing the batch.
| Call | Model | Job | Why this model |
|---|---|---|---|
| 1 | Sonnet | Read and assess fit | Reasoning matters most here |
| 2 | Haiku | Draft output | Cheap, high-volume, fast |
| 3 | Sonnet | Validate and catch failures | Catching bad output is worth the token cost |
The validator is the part most pipelines skip. It checks tone, length, factual accuracy against source data, and AI-pattern tells. If an output claims the entity “recently did X” but the scrape didn’t actually find that signal, the validator catches it. If the output uses three em-dashes in five sentences, the validator catches it. Production prompts are version-controlled and tested against a held-out set of real-world examples before any change merges.
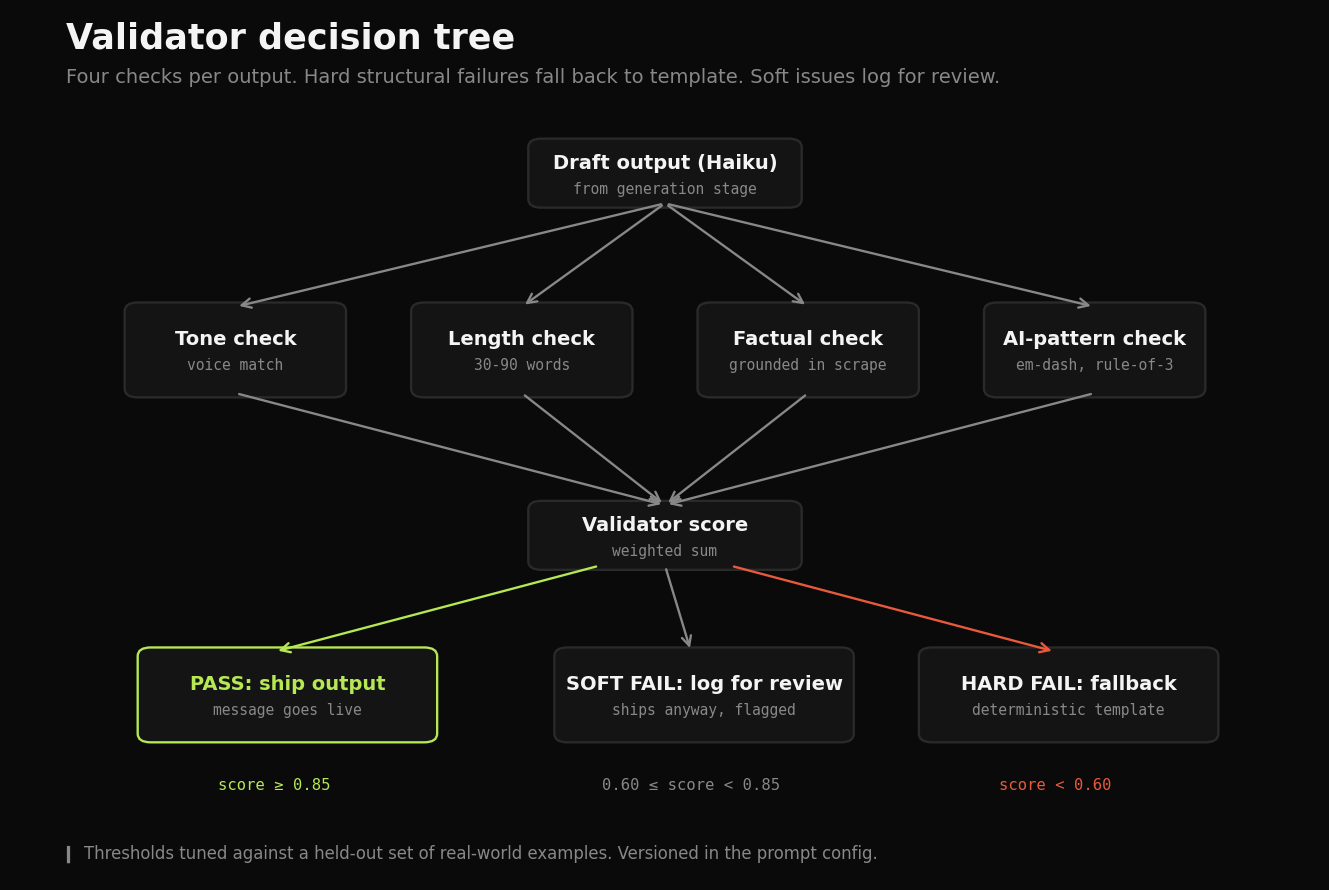 The validator runs four checks before any output ships. Hard structural failures fall back to deterministic templates.
The validator runs four checks before any output ships. Hard structural failures fall back to deterministic templates.
Every stage is independently rerunnable. If the scrape fails for a batch, stage 2 reruns without touching stages 1, 3, or 4. If a prompt update changes downstream output quality, stages 4-5 rerun on the existing scrape data. The system is observable from end to end.
 Independent rerunnability. A failed stage reruns without reprocessing upstream stages.
Independent rerunnability. A failed stage reruns without reprocessing upstream stages.
The outcome
The system runs on autopilot. Manual work shifted from drafting and routing to reviewing and exception-handling. The Monday morning summary tells the domain expert what worked last week, what broke, and what to look at. Three paragraphs. Numbers vs. last week.
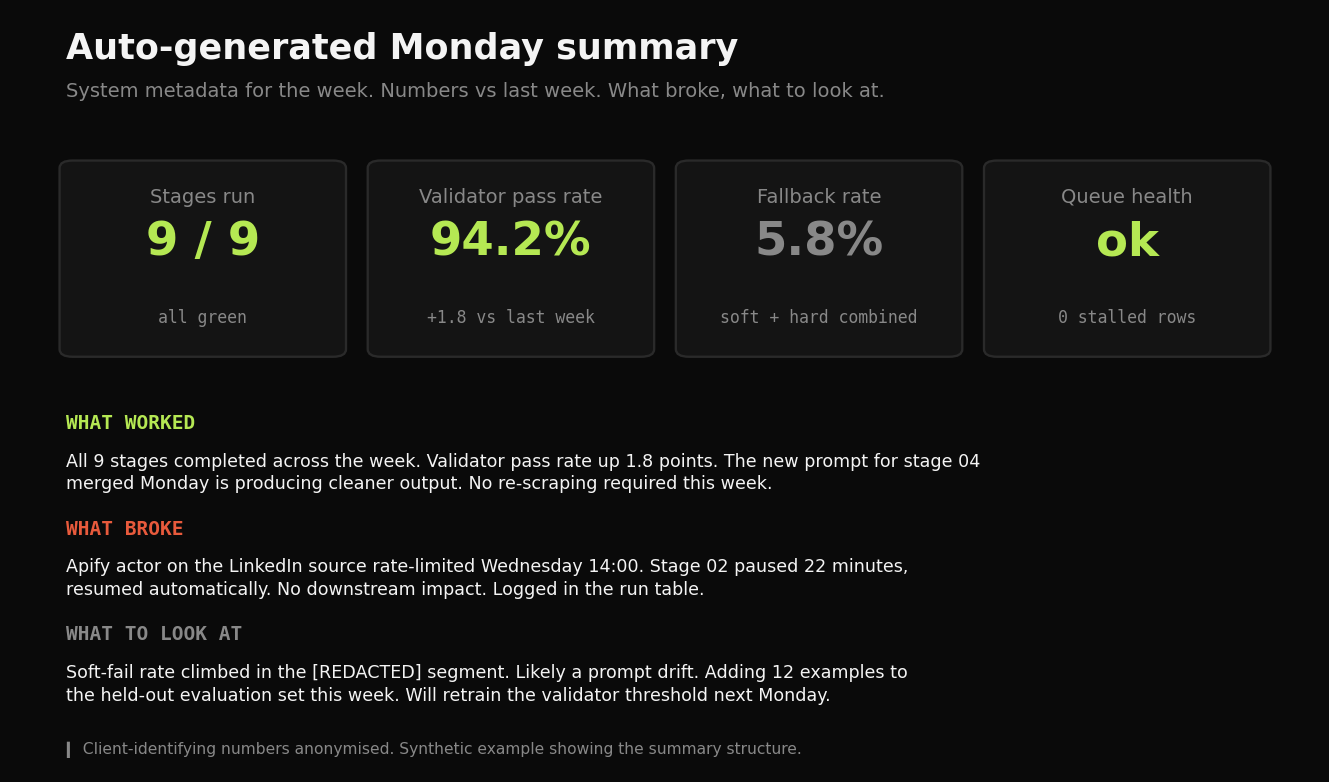 Auto-generated Monday summary. System metadata: stages run, fallback rate, validator pass rate, queue health. Client-identifying numbers anonymised.
Auto-generated Monday summary. System metadata: stages run, fallback rate, validator pass rate, queue health. Client-identifying numbers anonymised.
When a stage breaks, the alert reaches me before it reaches the user. Observability is half the engagement. The other half is the AI orchestration layer. The validator is what makes the AI output trustworthy at volume.
What I’d do differently
The first version of the validator was too aggressive. It triggered fallbacks to a generic template whenever the AI quality score dipped, even when the underlying output was structurally fine. A meaningful slice of records were getting the generic version when they should have been getting the personalised one. I caught it in the weekly review and tightened the trigger logic so only hard structural failures fall back to template.
The fix taught me a rule I should have built in from day one: every fallback decision needs to be logged with the reason. Observability beats post-hoc debugging every time.
Stack choices
The tool list is at the top of the page. The non-obvious decisions:
- Node.js for orchestration. Async I/O fits the queue-based architecture. Each stage is a small async function that reads from the queue, does its job, and writes back.
- Two data stores, two jobs. Airtable as the operational queue (cheap, easy domain-expert access, no migration overhead). PostgreSQL as the analytics warehouse (where the ML scoring model trains and the weekly reporting reads from).
- Claude API with Haiku + Sonnet routing. Cost predictability per record. The cheap model handles volume. The expensive model handles the calls where reasoning quality matters most.
- Apify + Clay for scraping and enrichment. Apify for source-specific scrapers, Clay for cross-source enrichment and waterfall lookups. Custom Python for the niche sources neither tool covers.
- GitHub Actions for scheduling. Free, version-controlled, and the retraining cron for the ML scoring model lives next to the code it retrains.
Want the technical deep-dive? Full code, queries, and reproducible analysis live on GitHub.
View on GitHub →