Agentic External Intelligence Platform
Personalised research, competitor monitoring, and weekly briefings replaced manual work for a B2B agriculture company. Live RAG dashboard, multi-LLM interpretation, cross-source signal detection, 228 sources.
228 sources, 7-layer scraper fallback, multi-LLM interpretation, RAG chat with citations, and a cross-source signal detector. Live at tomato-intel-api.onrender.com.
Outcome first
I built an agentic external intelligence platform for a B2B agriculture company. It does personalised research, competitor monitoring, and weekly briefings that used to take a person most of a week. Now the system does it in a few hours of compute and surfaces more than the manual version did.
The platform is live at tomato-intel-api.onrender.com. Leadership opens it on Monday morning, scans the weekly briefing, asks the chat panel a question, and acts on what they see. The job that used to require a full-time analyst is now a tool that the analyst uses.
Want the technical deep-dive: schema, scheduler internals, the full 7-layer scraper chain? See the GitHub case study.
Context
A B2B agriculture company operating across 27 countries needed continuous visibility across crop prices, regulatory shifts, competitor product launches, patent filings, and trade-press signals in three languages. Their team had one person reading source by source and writing a Monday briefing. The briefing was always behind, always incomplete, and always limited to whatever that one person had time to read.
The brief was simple. Replace the manual job with a system that collects, interprets, and surfaces only what matters. Personalised to their stack, their competitors, and their decisions.
The problem
Agriculture commercial teams work across regulatory shifts, competitor moves, price signals, and patent activity. The information exists. It just lives in 200+ disconnected sources, in three languages, and nobody has time to read them all. Manual monitoring at this scope is structurally broken. Every commercial team in this space is making decisions on stale signals.
This client was no exception. The team was making weekly commercial decisions on signals that were stale by the time they read them. Three concrete failure modes kept showing up:
- A regulatory change in one EU country would apply bloc-wide six weeks later. The team would find out from a customer, not from their own monitoring.
- A competitor would launch a new product in a region. The team would hear about it months later from a sales rep who lost a deal.
- A price movement would break a recent trend. By the time it hit the briefing, the window to react was closed.
This is a structural problem, not a staffing one. One person reading 200+ sources in three languages misses things, two people miss different things, and hiring three more analysts doesn’t change that.
The approach
I framed the build as five jobs the system has to do, each replacing a different piece of the manual workflow.
Job one: scraping. Get content from 200+ sources reliably, including the ones that fight back. I built a cost-sorted fallback chain. Free layers run first (RSS, raw HTML, Crawl4AI, Playwright, Jina). Money-spending layers (Firecrawl, Apify) only fire when free layers fail. A is_required flag unlocks a final Claude rescue for must-have sources. 228 sources across 10 categories.
Job two: interpretation. Don’t store raw articles. Read them. Every incoming item runs through Claude Haiku on a 90-minute cron. The model detects language, translates if needed, generates an English title and summary, scores relevance 0-10, and tags by topic and region. Boilerplate (relevance 1) gets filtered out before the frontend ever sees it.
Job three: retrieval. Make the corpus searchable in the way leadership actually thinks. Embeddings via Voyage AI, stored in pgvector. The chat panel composes answers from the top-k retrieved articles using cosine similarity. Citations render Perplexity-style as clickable pills. “What patent activity has there been on drought-tolerant tomato varieties this quarter?” becomes a one-paragraph answer with five linked sources.
Job four: routing. Use the right model for the right job. Claude Haiku does bulk classification cheaply. Claude Sonnet does cross-source synthesis when the question is hard. DeepSeek-V3 covers non-English sources. Perplexity covers real-time web search. A judge pattern fans out hard questions to multiple models and lets Sonnet reconcile the answers.
Job five: signal detection. Reading articles tells you what each one says. It doesn’t tell you what’s happening across them. A competitor filing a patent is a data point; that same competitor filing a patent, raising money, and showing up in a regulatory notice in the same week is a move, and no single article reports it as one. So the system reduces articles to named entities, then runs a deterministic rule engine over the entity-to-source graph: it flags when one entity surfaces across several unrelated sources, or across several different kinds of source (patent, funding, regulation) at once. Signals rank against each customer’s watchlist, and every signal links back to the verbatim quotes it was built from, so a flagged “move” is always one click from its evidence, never a model’s unsupported guess.
The build
The platform runs as one FastAPI service on Render. It serves the API and the React dashboard from the same origin so there’s no CORS surface and no second host to maintain. APScheduler runs the cron jobs in-process. Supabase Postgres holds everything, with pgvector for embeddings and row-level security for access control.
Three things matter most in the build.
The agentic scraper. Traditional scrapers are scripted. They break when a source changes layout. This one isn’t. The agent has a small toolset (apify_actor.run, http_get, parse_article, store, mark_source_failed) and plans its own sequence using Claude’s tool-use API. When a source fails, the agent picks a different tool and tries again. When it can’t recover, it flags the source for review. No human babysits the scrape.
The RAG chat. This is the surface leadership actually uses. The user asks a question in plain English. The system retrieves the top-k relevant interpreted items via pgvector. A query_company_context tool pre-pends the company’s profile and their tracked competitors to the prompt so the answer is personalised. Claude generates the response with [1], [2], [3] citation markers that the frontend renders as clickable pills.
The signal detector. Deliberately not an LLM. Every rule is a SQL aggregation or a numeric comparison, so a signal is auditable and reproducible rather than a model’s opinion. Five rules run over the entity graph (cross-source convergence, weak signal, anomaly versus a 30-day baseline, first-mover, geographic spread), and each rule suppresses itself with a logged reason when its data precondition isn’t met, instead of firing noise. The honest limit: convergence only triggers when the same specific entity recurs across sources, which is uncommon in any single week at this volume, so signal density grows as history accumulates. The mechanism is built and verified end-to-end; the discipline is that it would rather show nothing than show a generic non-signal.
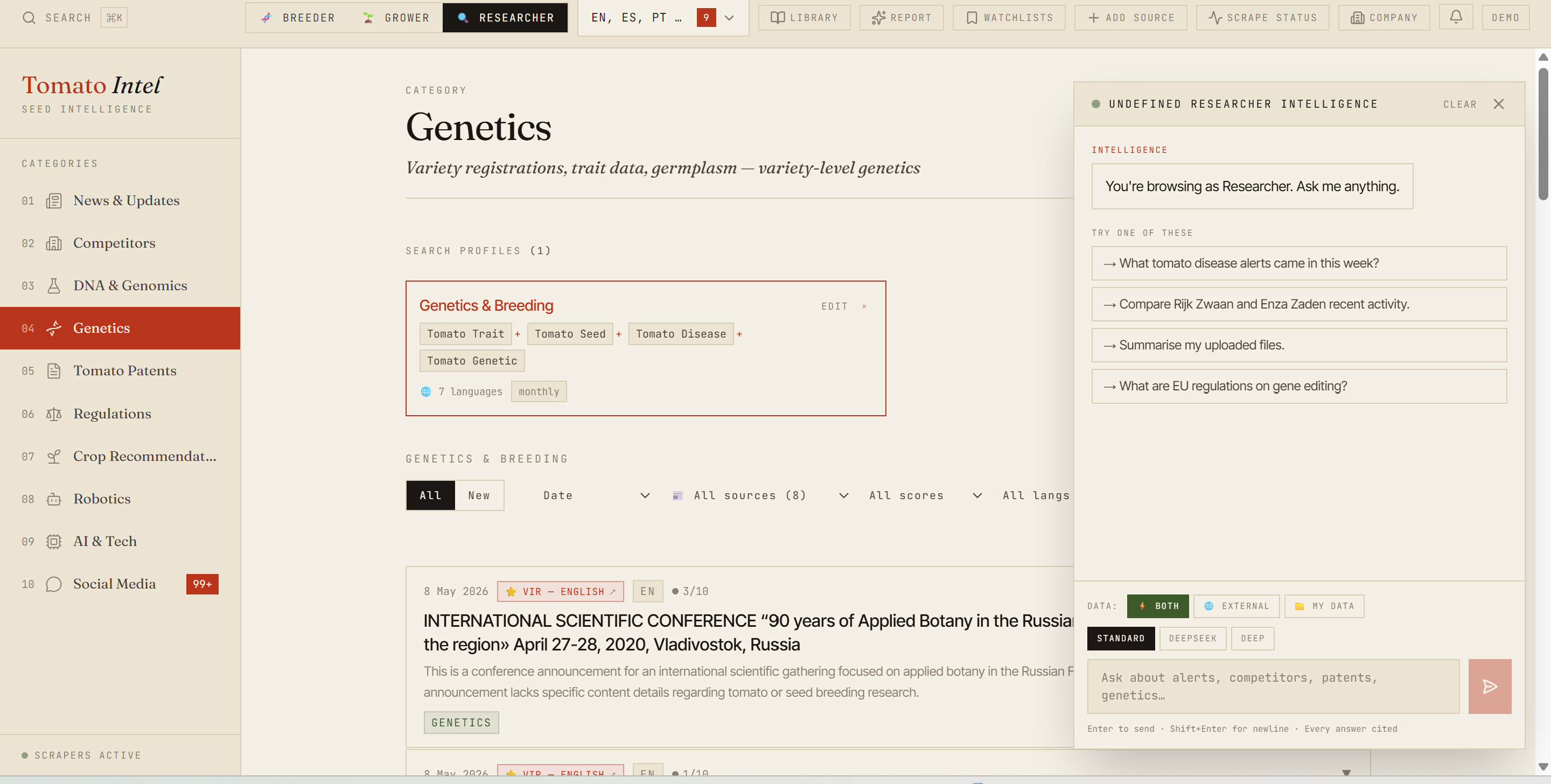 Chat answers compose from retrieved articles. Citations render as clickable pills back to source.
Chat answers compose from retrieved articles. Citations render as clickable pills back to source.
I also built a second agent for non-technical users. The ScraperBuilder lets someone paste a URL into the dashboard. The agent proposes a scraper config, tests it live with SSE streaming, and offers a one-click “add to sources” button. The team can extend their own source list without a developer.
Everything is observable. Every scrape run writes a row to a scrape_runs table with source, status, items found, duration, and any error. The Scrape Status panel in the dashboard renders the history with All / Mine / Failing filters and a “Run now” button per source. When a source goes silent, it gets flagged before it becomes a blind spot.
The outcome
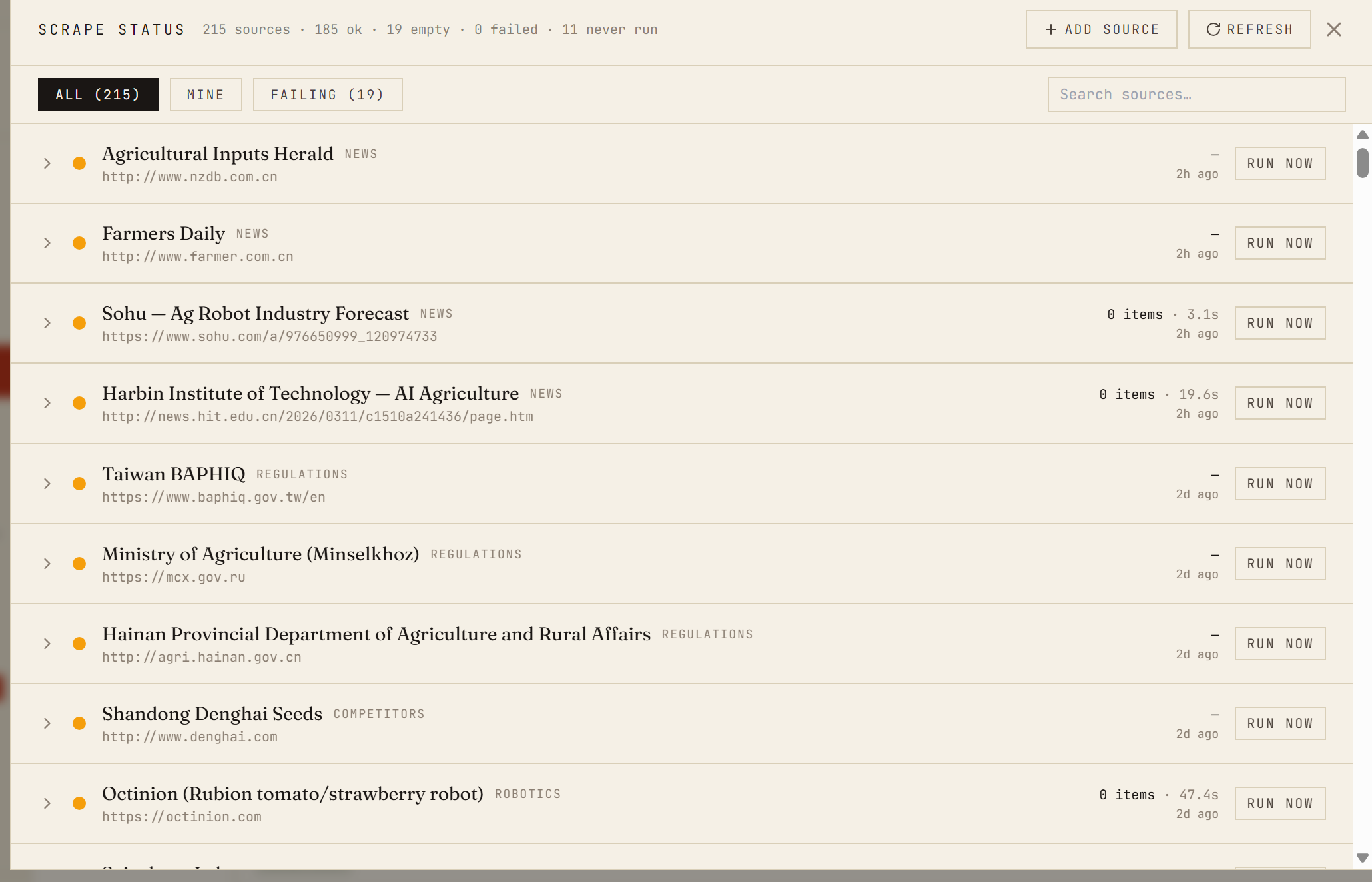 Scrape Status panel: per-source health, last run, items found, and a Run now button. About 240 run rows logged per day.
Scrape Status panel: per-source health, last run, items found, and a Run now button. About 240 run rows logged per day.
Manual hours dropped. The weekly briefing job that used to take most of a week now runs in a few hours of compute and produces a longer, better-cited document than the human version did.
Decisions improved. Leadership stopped getting blindsided by regulatory shifts and competitor launches. The chat panel turned weekly questions into Monday-morning lookups. Personalisation against tracked competitors made the signal actually relevant, not just “agriculture news.”
The numbers that matter: 228 active sources across 10 categories. Hundreds of articles interpreted a day. ~470 junk rows purged in cleanup passes. 13 external services wired together. A five-rule signal detector over a conformed entity graph. $7 a month to host, $35 every three months for the Apify budget. One person built it.
The deeper outcome is harder to measure. Leadership stopped asking “is anyone watching this?” and started asking “what should we do about it?” That shift is the actual product. The platform underneath is just what it took to get there.
What the business should do next
The platform works; the next gain isn’t technical, it’s behavioural. The recommendation is to make the Monday briefing the start of one standing decision meeting, not a document people skim alone. The system already surfaces what’s moving, a competitor converging across patent, funding, and regulatory sources in the same week, or a price break against the 30-day baseline. But a signal only pays off if someone owns the response. Assign each tracked competitor and each signal category an owner, and give the meeting a single job: for every signal the platform raised that week, decide act, watch, or ignore, and write the decision down. That turns the tool from a feed into a habit, and it produces the one thing the platform can’t generate on its own, a record of which signals led to a good call, which the team can use to tune the watchlist over time. The build replaced a week of manual reading; this turns the hours it gave back into decisions.
What I’d do differently
About 21 sources are permanently blocked. China gov portals, Hainan, mcx.gov.ru, AgWeb. Cloudflare or geo-IP gated. Even with the full 7-layer chain plus Apify plus Claude rescue, none of them open up. Cracking them needs paid residential proxies with CN and RU IPs. I chose not to spend that money for this build. If I rebuilt, I’d budget for it from day one.
I also removed Voyage embeddings from the keyword search path partway through. Semantic search was costing more than it returned for the keyword-heavy queries users actually ran. The embeddings stay in the RAG chat where they earn their keep. The /search/smart endpoint runs as a PostgREST keyword query now. Honest tradeoff. I’d make the same call again, just sooner.
Tools
FastAPI, Python, Supabase (PostgreSQL with pgvector), Apify, custom Python scrapers (trafilatura, Playwright, selectolax, feedparser), Claude API (Haiku and Sonnet, routed by task), Voyage AI for embeddings, DeepSeek-V3 for non-English, Perplexity for real-time search, APScheduler for cron, React + Vite + Tailwind on the frontend, Render for hosting, Sentry and PostHog for observability.
Want the technical deep-dive? Full code, queries, and reproducible analysis live on GitHub.
View on GitHub →